今天解读这篇发表于《自然-生物工程综述》的重磅文章。这篇综述全面梳理了大型语言模型(LLM)在医学领域的应用现状、核心技术、挑战与未来机遇,为我们描绘了一幅AI技术如何深度变革医疗健康的宏伟蓝图。
解码未来医疗:顶级综述深度剖析AI大模型如何颠覆医学
自ChatGPT等大型语言模型(LLM)问世以来,它们理解和生成人类语言的惊人能力吸引了全世界的目光。这股浪潮也迅速席卷了严谨复杂的医学领域。从辅助临床诊断到革新医学教育,LLM展现出了巨大的潜力。然而,我们对这项技术在医学领域的全面发展、实际应用和最终成果的评估仍显不足。
这篇于2025年发表在国际顶尖期刊**《自然-生物工程综述》** 上的文章,正是为了填补这一空白。它系统性地回顾了医学LLM的开发部署、面临的挑战与机遇,为我们理解“AI医生”的现状与未来提供了权威的视角。
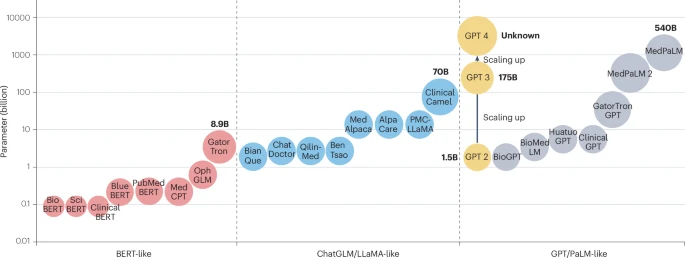
第一部分:AI医生的“成长之路”——医学大模型的炼成秘籍
一个通用的大模型(如GPT、LLaMA)是如何转变为能够理解复杂医学知识的“专家”的?文章指出,这主要通过三种核心技术路径实现:
预训练(Pre-training)、微调(Fine-tuning)和提示(Prompting)。
1.1 从零开始:预训练 (Pre-training)
这是最基础的一步,相当于为AI模型构建医学知识的基石。研究人员会将海量的医学文本,如医学文献(PubMed)、临床笔记(MIMIC-III数据库)等,投喂给模型。通过“完形填空”(掩码语言建模)或“下文预测”(下一个词元预测)等任务,模型能自主学习到医学术语的内在联系和语言规律,从而获得丰富的医学背景知识。像BioBERT、GatorTron等早期模型就是通过这种方式训练出来的。
1.2 青出于蓝:微调 (Fine-tuning)
从头训练一个医学大模型耗时耗力且成本高昂。更高效的方法是站在通用LLM的肩膀上,用专业的医学数据对其进行“特训”或“微调”,使其适应医学领域的特殊需求。
知识灌输(Supervised Fine-tuning, SFT):
这类似于给模型“刷题”。研究人员使用高质量的医学语料,如医患对话、医学问答对、知识图谱等,对通用LLM进行持续训练。其目标是向模型注入更多的医学知识,让它更懂医学。例如,ChatDoctor模型就是通过在医患对话数据上微调LLaMA而来的。
指令学习(Instruction Fine-tuning, IFT):
相比于单纯灌输知识,IFT更侧重于训练模型“听懂指令”的能力。它使用包含“指令-输入-输出”格式的数据集,教会模型如何根据人类的指令完成特定任务,而不是简单地预测下一个词。IFT强调训练数据的“质量和多样性”。近年来兴起的多模态模型,如Med-Gemini,更是通过包含医学影像和文本的指令数据进行训练,让模型学会看图说话,识别异常并生成诊断报告。
高效调优(Parameter-efficient Fine-tuning, PEFT):
为了进一步降低微调的计算成本,研究者开发了PEFT技术。其核心思想是冻结预训练模型的大部分参数,只对一小部分(新增或修改的)参数进行训练。以
LoRA技术为例,它通过在模型的每一层中加入可训练的“低秩矩阵”来实现高效微调,大大减少了计算和内存需求,同时保持了强大的性能。
1.3 巧妙引导:提示工程 (Prompting)
这是最轻量级的方法,它不改变模型任何参数,而是通过精心设计的“提示语”(Prompts)来引导通用LLM在医学领域发挥作用。
举一反三(In-context Learning, ICL):
在向模型提问时,同时给它一两个“范例”(示例),模型就能模仿范例的格式和逻辑来回答问题。这种方法无需大量标注数据,非常灵活。
思维链(Chain-of-Thought, CoT):
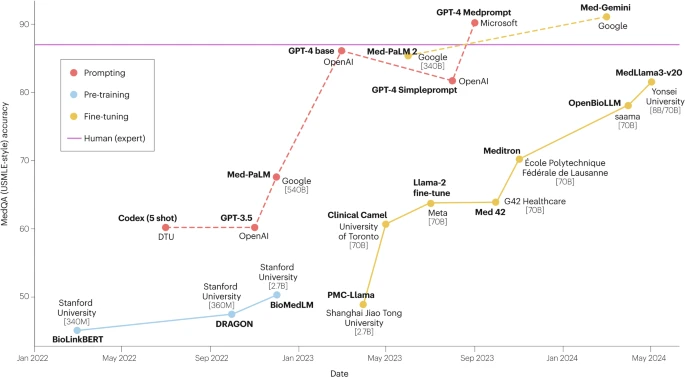
为了让模型的回答更具逻辑性和准确性,CoT技术引导模型在给出最终答案前,先生成一步步的“推理过程”。这尤其适用于复杂的医学问答任务,能让模型的诊断过程更透明、更可解释。MedPrompt就是直接利用CoT等提示技术,让通用模型GPT-4在医学问答上的表现甚至超越了经过微调的专业医学模型。
外挂知识库(Retrieval-augmented Generation, RAG):
这是对抗模型“幻觉”(生成不实信息)的利器。当模型遇到一个问题时,RAG系统会先从一个外部的、可信的知识库(如最新的临床指南、权威医学文献)中检索相关信息,然后将这些信息作为上下文一起提供给模型,辅助它生成更准确、更可靠的回答。这种方法尤其适用于知识快速迭代的医学领域,因为它能确保模型获取最新的信息,而无需重新训练。
第二部分:AI医生的“能力考核”——在真实医疗任务中的表现
文章将医学任务分为两大类:
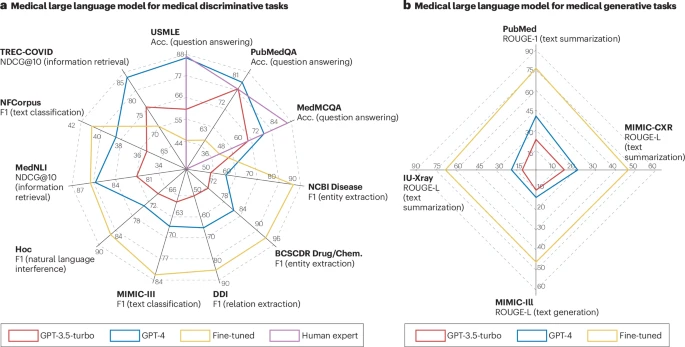
判别式任务(如分类、提取信息)和生成式任务(如生成摘要、报告)。通过对比通用LLM(GPT-3.5/GPT-4)、领域内微调模型以及人类专家的表现,文章揭示了一个有趣的现象:
“选择题”高手:在有明确选项的问答任务(如美国执业医师资格考试USMLE)中,强大的通用LLM(如GPT-4)表现极为出色,其准确率甚至可以媲美乃至超越人类专家。这可能是因为这类任务是“闭卷”的,正确答案已经包含在选项中,模型强大的推理和知识匹配能力得以充分发挥。
“开放题”的挑战:然而,在没有预设选项的开放式任务中(如从病历中提取特定实体、生成报告摘要等),通用LLM的表现则普遍不如那些针对特定任务进行过精细微调的“轻量级”模型。例如,在实体提取任务中,微调后的BioBERT模型的F1分数远高于GPT-4。这说明,真实的临床实践往往是开放式的,对模型的精准性和专业性要求极高,通用模型仍有提升空间。
第三部分:AI医生的“临床实习”——七大前沿应用场景
尽管多数医学LLM仍处于研发阶段,但它们已经在多个临床场景中展示了巨大的应用潜力。
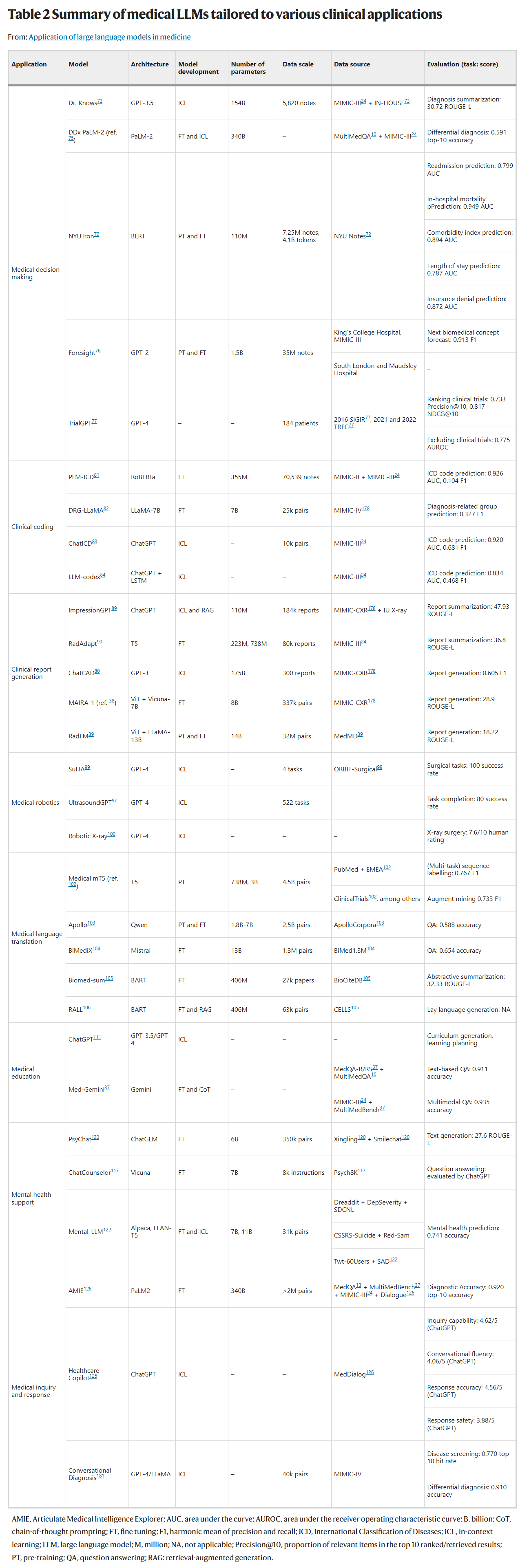
辅助诊疗决策 (Medical Decision-making)
LLM能够快速整合来自病史、临床数据和最新文献的海量信息,为医生提供诊断、预后、治疗方案建议。例如,
NYUTron模型能预测住院死亡率、再入院风险等多种临床事件 39;TrialGPT则可以帮助患者匹配合适的临床试验,大大缩短了筛选时间。自动化临床编码 (Clinical Coding)
将诊断、操作等信息转化为标准化的代码(如ICD编码)是医疗管理和医保支付的关键环节,但人工编码耗时且易出错。LLM可以自动从临床文本中提取关键术语并分配相应代码,提高效率和准确性。
生成临床报告 (Clinical Report Generation)
撰写放射学报告、出院小结等是临床医生的繁重工作之一。LLM可以作为得力助手,自动生成或总结这些报告,减轻医生负担。特别是多模态LLM,能够结合医学影像和文本提示,直接生成图文并茂的诊断报告。
赋能医疗机器人 (Medical Robotics)
LLM正在为医疗机器人注入“智慧大脑”,提升它们的决策、交互和控制能力。例如,在手术机器人中,LLM可以辅助进行高阶规划和低阶控制,实现更精准的操作。在超声检查中,
UltrasoundGPT能利用领域知识实现精确的运动规划,提高扫描速度和图像质量。打破语言壁垒 (Medical Language Translation)
LLM的应用主要体现在两个方面:一是将专业医学术语在不同语言间进行精准翻译 4949;二是对普通民众进行“科普”,将复杂的医学行话转化为通俗易懂的语言,促进医患沟通。
革新医学教育 (Medical Education)
LLM可以成为医学生的“全天候导师”。它能生成个性化的学习模块、模拟临床案例、回答疑难问题,甚至提供苏格拉底式的辅导,为学生创造超越传统教科书的丰富学习体验。
提供精神健康支持 (Mental Health Support)
心理治疗很大程度上依赖于对话。LLM作为优秀的对话伙伴,有潜力为面临经济或物理障碍的患者提供初步的心理支持,提高精神健康服务的可及性。模型如
PsyChat和Chat Counselor正被开发用于提供共情、相关的治疗性对话。
第四部分:通往未来的荆棘路——AI医生面临的严峻挑战
尽管前景广阔,但将LLM安全有效地融入临床实践,仍需克服重重障碍。
“一本正经地胡说八道”:幻觉问题 (Hallucination)
这是LLM最核心的风险之一。模型可能会生成看似流利、合理但实际上完全错误的信息,这在医疗领域可能导致错误的诊断和治疗,后果不堪设想。
评价标准缺失:评估困境 (Lack of Evaluation Benchmarks)
现有的评测基准大多集中在医学问答任务上,无法全面评估模型在真实临床场景中的可信赖性、可解释性和实用性。用人类的标准化考试来评估AI,并不能完全反映其在复杂临床环境中的真实能力。
数据难题:数据孤岛与知识更新 (Data Limitations & Knowledge Adaptation)
高质量的医学数据因涉及伦理、法律和隐私问题而难以获取,导致现有医学LLM的训练数据规模远小于通用模型。此外,医学知识日新月异,如何经济、高效地为已训练好的模型注入新知识,同时让其“忘记”过时的旧知识,是一个巨大的技术挑战。
不可逾越的红线:行为、伦理与安全 (Behavior, Ethics, and Safety)
如何确保模型的行为符合医学伦理和专业准则?如何保护患者的隐私数据不被泄露?一旦出现医疗差错,责任该如何界定?这些都是在技术应用前必须解决的根本性问题。
监管的脚步:法规挑战 (Regulatory Challenges)
与传统的、用途单一的AI医疗技术不同,LLM功能强大且应用广泛,这给现有的监管框架带来了巨大挑战。监管机构需要开发更快速、更具适应性的框架,以确保LLM医疗技术的安全、合规,同时又不扼杀创新。
第五部分:展望未来——更强大、更全面的智能医疗伙伴
文章最后对未来发展方向进行了展望,指出了几个关键趋势:
迈向多模态融合 (Multimodal LLMs):未来的医学AI将不仅能处理文本和图像,还将融合心电图、血压等时序数据,形成对患者状况更全面的理解。
智能体(Agent)的兴起 (LLM-based Agents):未来的研究方向是开发基于LLM的自主智能体。这些智能体能像人类专家团队一样,模拟不同科室的医生角色,协同工作,整合各种检查报告,最终形成一个综合性的诊疗意见。
呼唤跨界深度合作 (Interdisciplinary Collaboration):文章强烈呼吁,医学专业人士不能只做技术的“使用者”,而应积极参与到医学LLM的开发、训练和测试中,提供专业的训练数据,定义真正有价值的应用场景,并在真实世界中检验其成效。培养兼具医学和AI知识的“双语”人才也至关重要。
总而言之,这篇综述为我们清晰地展示了大型语言模型在医学领域的巨大潜力和必经的挑战。AI医生不会轻易取代人类医生,但它正朝着成为人类医生不可或缺的智能伙伴、高效助手和知识外脑的方向坚定迈进。这条变革之路充满挑战,但无疑也预示着一个更智能、更高效、更个性化的医疗新时代的到来。