【Nat. Mach. Intell.】 告别昂贵染色!AI凭一张普通病理切片,竟能“凭空”生成11种关键蛋白图像!
今天,咱们来聊一个和每个人的健康都息息相关的话题——癌症诊断。如果你或你的家人有过看病理报告的经历,你一定见过那种染成紫色和粉色的组织切片。这就是大名鼎鼎的“H&E染色”,一百多年来,它一直是病理科医生诊断癌症的“金标准”。它成本低、速度快,是当之无愧的“劳模”。
但是,这位“劳模”也有自己的烦恼。H&E染色展现的主要是细胞的形态结构,就像一张黑白素描画。而要想真正看清肿瘤内部的“势力分布”——比如哪些是癌细胞,哪些是前来战斗的免疫细胞,它们之间是如何“排兵布阵”的——我们就需要更高级的“彩色画笔”。
这种“彩色画笔”就是多重蛋白成像技术(比如多重免疫荧光 mIF/IHC)。它能同时给一张切片上的几十种不同蛋白质(我们称之为“生物标志物”)打上不同的颜色标签。如此一来,肿瘤微环境(TME)这个复杂的战场就一目了然了。这对于判断病情、预测治疗效果,尤其是评估免疫治疗是否有效,至关重要。
然而,理想很丰满,现实很骨感。这种高级的“彩色笔”实在是太贵、太慢、太消耗组织了!一套流程下来,动辄数千上万,耗时数天,而且只能分析一小块组织区域。这使得它很难在临床上大规模普及,成为精准医疗发展道路上的一大障碍。
那么,有没有可能,我们只用最便宜、最快速的“黑白素描”(H&E图像),却能看到“彩色全景图”(多重蛋白表达)的效果呢?
就在最近,来自苏黎世联邦理工学院(ETH Zurich)和巴塞尔大学医院的顶尖学者们给出了一个惊人的答案:能!
他们开发出一种名为 HistoPlexer 的深度学习框架,就像一个拥有“火眼金睛”的AI画家。它只需要一张常规的H&E染色图像,就能直接“脑补”并生成出11种关键蛋白质的空间分布图!111这项颠覆性的成果发表在了国际顶级期刊**《自然·机器智能》**上 2 ,为我们揭示了AI在病理诊断领域的无限潜能。
AI画家的修炼秘籍:HistoPlexer是如何炼成的?
要想让AI学会“看图生图”,可不是件容易事。你不能简单地告诉它“这里像肿瘤,那里像免疫细胞”,它需要通过海量的数据学习,自己领悟H&E图像的形态特征和蛋白质表达之间的微妙联系。
HistoPlexer的核心架构,是一种叫做**条件生成对抗网络(cGAN)**的深度学习模型。你可以把它想象成一个由两位高手组成的修炼体系:“生成器”(一个天才画家)和“判别器”(一个顶级鉴赏家)。
天才画家(生成器 G):它的任务是接收一张H&E图像(输入条件),然后凭空画出一幅对应的多重蛋白图像(生成的IMC图像)。它一开始完全是瞎画,但目标是画得越来越逼真。
顶级鉴赏家(判别器 D):它的任务是评判画作的真伪。它会同时看“天才画家”的作品和真实的蛋白图像(我们称之为“金标准” Ground Truth),然后给出一个分数,判断这幅画是“生成的”还是“真实的”。
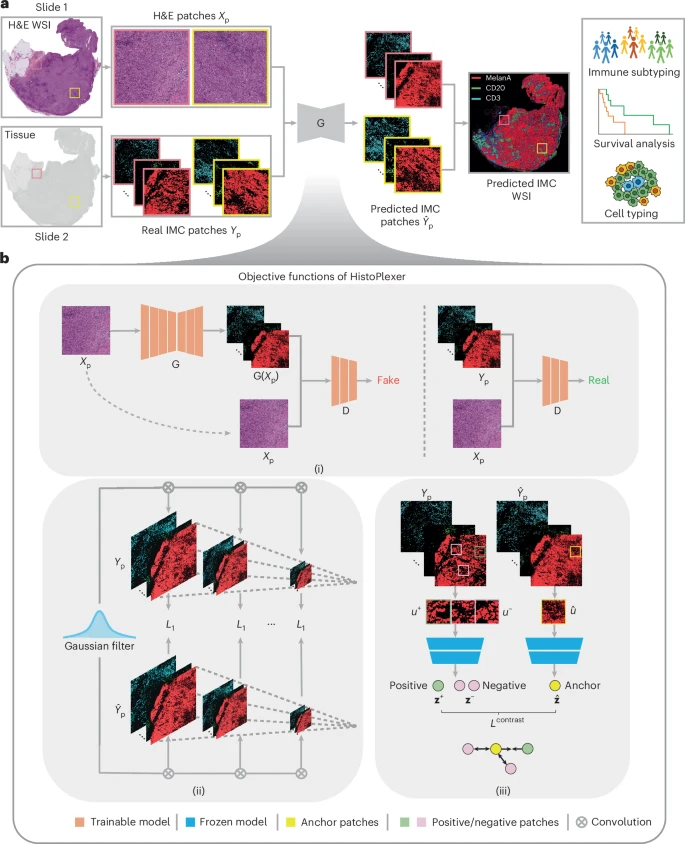
图1:HistoPlexer 工作流程及目标函数示意图。
整个训练过程,就是一场两位高手的“相爱相杀”:
画家(生成器)拼命地画,试图骗过鉴赏家。
鉴赏家(判别器)则拼命地学习,提高自己的眼力,不放过任何一个瑕疵。
通过这种持续的对抗博弈,画家的画技(生成图像的真实性)会越来越高超,直到鉴赏家再也分不清真假为止。
但是,仅仅“画得像”还远远不够。研究团队面临一个巨大的现实挑战:H&E图像和用于训练的真实蛋白图像(来自IMC技术)通常取自连续的组织切片,而不是同一张。这意味着,尽管组织的大体结构一致,但细胞的精确位置会有毫米级的偏差。如果强行要求AI在像素级别上做到一模一样,就像要求一位画家精确复制另一幅画上每一根飘动的发丝,这既不现实,也无必要。
为了解决这个“切片间差异”问题,HistoPlexer的开发者们为这位AI画家设定了三条独门的修炼心法,也就是定制化的损失函数:
心法一:多尺度高斯金字塔损失 (Gaussian pyramid loss)
这相当于告诉画家:“你的画在整体构图和局部细节上都要和原作神似,但我们不苛求每一个像素点都完全对齐。” 它通过在不同分辨率(尺度)上比较生成图像和真实图像的相似度,放宽了对像素级精确对齐的要求,使得模型更加鲁棒。
心法二:多层面对比损失 (Patch-wise contrastive loss)
这条心法更进一步,它要求:“在你的画中,与原作中某个区域(比如一小块肿瘤细胞聚集区)相对应的区域,在深层特征上(embedding-level)应该非常接近,而与原作中其他不相关的区域则要保持距离。” 这确保了模型能学习到局部区域内在的、有生物学意义的特征,而不仅仅是模仿表面的纹理。
心法三:联合预测,而非逐个击破 (Multiplex Prediction) 这是HistoPlexer最核心的优势之一。以往的方法通常是一个模型预测一种蛋白,最后再把结果拼起来。而HistoPlexer则用一个模型同时预测全部11种蛋白 。这样做的好处是,模型能够学习到不同蛋白质之间的内在关联和共存模式。比如,它会学到CD3和CD8a这两种T细胞标志物经常一起出现。这种“全局观”让它在预测那些表达量很低、信号很弱的稀疏蛋白时,能够借助其他丰富蛋白的形态信息,从而获得远比“单打独斗”更精准的结果。
通过这套精妙的“修炼体系”,HistoPlexer在来自转移性黑色素瘤患者的336对H&E-IMC图像上进行了严苛的训练和测试,最终成功出师,掌握了从一张普通H&E切片“凭空”生成11种蛋白全景图的非凡能力。
AI画家的毕业大作:效果如何?是“照骗”还是真迹?
“王婆卖瓜,自卖自夸”可不行。HistoPlexer的生成效果究竟如何,必须用数据和事实说话。研究团队从多个维度,对它的“毕业作品”进行了一场堪称严苛的“终极考核”。
第一关:量化指标大比拼——跑分我最高!
研究人员选择了多种图像质量评估指标,如多尺度结构相似性(MS-SSIM)、峰值信噪比(PSNR)和均方根误差(RMSE-SW),将HistoPlexer与Pix2Pix等基线模型进行了正面PK 。
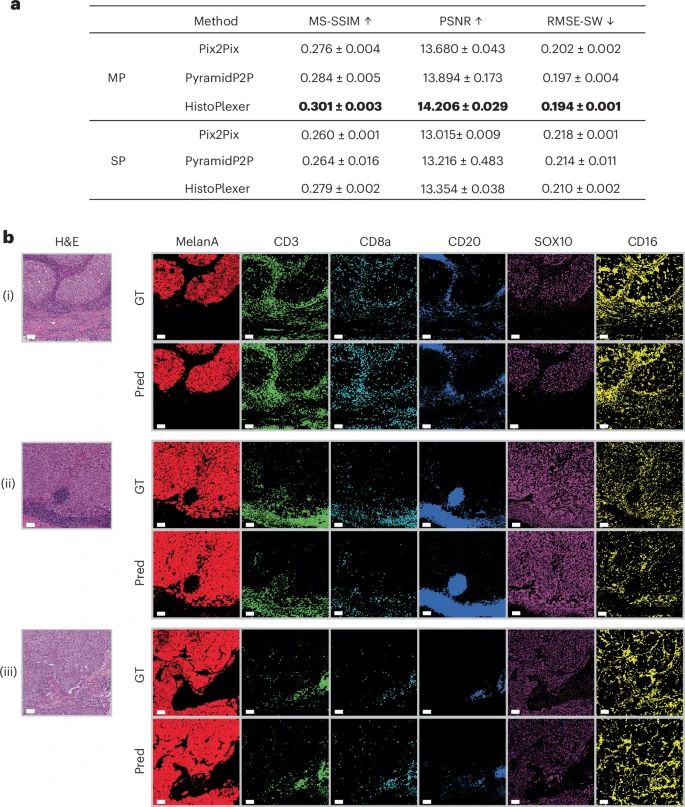
图2:HistoPlexer在各项图像质量评估指标上均优于基线模型。
结果毫无悬念(见上图),在同时预测所有标志物的多重(MP)模式下,HistoPlexer在所有关键指标上都取得了最优成绩,生成的图像与“金标准”最接近 。并且,所有模型的MP模式都优于一次只预测一种蛋白的单重(SP)模式,这有力地证明了“联合预测”策略的巨大优势 。
第二关:专家评审——连火眼金睛的病理学家都难辨真伪!
跑分高不代表一切,生成的图像是否“看起来真实”,还得由人类专家说了算。研究团队采用了一种名为**HYPE(人眼感知评估)**的框架,让病理学专家来玩一个“找不同”的游戏 。他们把真实的蛋白图像和HistoPlexer生成的图像混在一起,让专家判断真伪。
结果非常有趣:专家们将61.6%的淋巴细胞标志物生成图和72.8%的肿瘤标志物生成图误认为是真实的!16 这意味着,在超过一半的情况下,AI的作品成功“骗”过了训练有素的专家。这充分说明HistoPlexer生成的图像在视觉上达到了以假乱真的地步。
第三关:生物学意义验证——不只是画皮,更能画骨!
一幅好的病理图像,美观是其次,最重要的是能准确反映生物学信息。HistoPlexer生成的图像能做到这一点吗?
- 细胞类型识别:
研究团队首先利用生成的蛋白图谱来识别细胞类型。结果令人振奋,无论是肿瘤细胞、B细胞,还是CD4/CD8 T细胞,HistoPlexer生成的细胞类型分布图(Pred cell types)与基于真实IMC数据得到的分布图(GT cell types)高度一致 。特别是在区分“免疫热点”(immune 'hot',大量免疫细胞浸润)和“免疫冷点”(immune 'cold',缺乏免疫细胞)的肿瘤时,AI的预测与真实情况几乎完美匹配 。
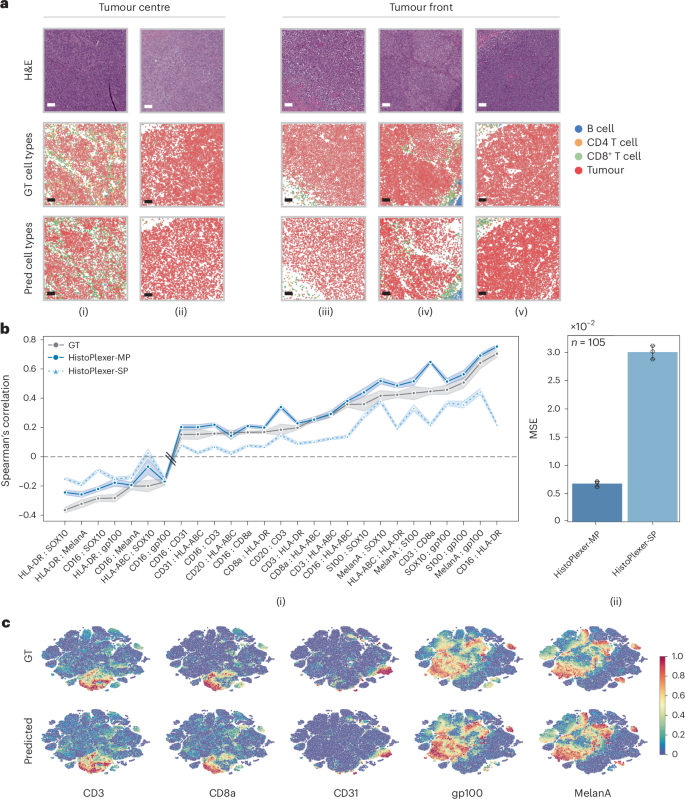
图3:HistoPlexer生成的细胞类型图(下)与真实细胞类型图(中)高度吻合。来源:参考文献 19
- 空间共定位模式:
在肿瘤微环境中,不同细胞和蛋白的相对位置关系(即空间模式)蕴含着丰富的生物学信息。研究团队通过计算蛋白之间的“斯皮尔曼相关系数”来评估HistoPlexer是否保留了这些重要的空间关系 。
结果再次证明了“联合预测”(MP)的威力。相较于“单打独斗”(SP),HistoPlexer-MP模型生成的蛋白共定位模式与真实值的均方误差(MSE)低了整整一个数量级 21!这意味着它极其精准地复现了真实组织中蛋白质之间的空间邻近关系,比如哪些蛋白总是“抱团”出现,哪些总是“井水不犯河水”。
第四关:临床应用实战——预测患者生存率,我是神助攻!
最终的考验,是看这项技术能否在真实的临床场景中发挥价值。研究团队将HistoPlexer应用到了一个完全独立的患者队列——**TCGA黑色素瘤(TCGA-SKCM)**数据集上 。
他们进行了两项极具挑战性的任务:预测患者生存风险和对患者进行免疫亚型分类 。
研究者设计了两种预测模型:
单模态模型:仅使用传统的H&E图像特征。
多模态模型:将H&E图像特征与HistoPlexer生成的蛋白图像特征(MelanA, CD3, CD20)融合在一起。
结果令人瞩目:
在生存预测任务中,融合了AI生成信息的“多模态模型”,其预测准确性(时间依赖性C-index)比“单模态模型”提升了3.18% 。
在免疫亚型分类任务中,这种提升更加惊人,加持了HistoPlexer的模型的加权F1分数暴涨了17.02% 25!
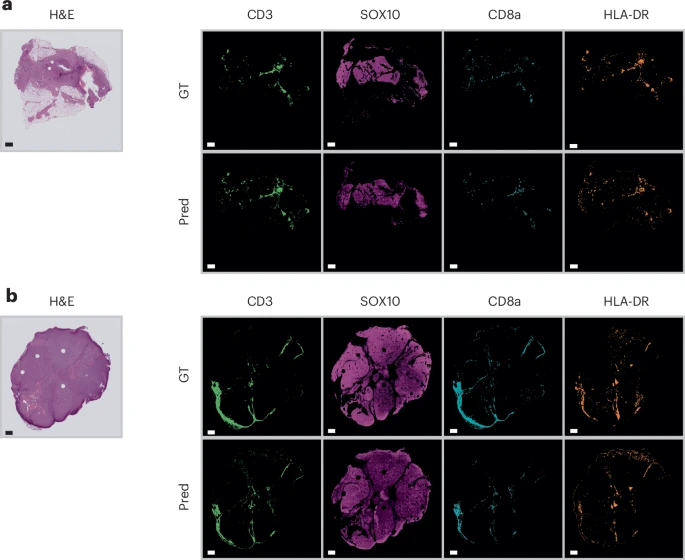
图4:在生存预测和免疫亚型分类任务中,融合了HistoPlexer生成特征的多模态模型(Multimodal)显著优于仅使用H&E的单模态模型(Unimodal)。
这组数据掷地有声地证明了:HistoPlexer生成的虚拟蛋白图像,并非华而不实的“特效”,而是包含了真实、有效、且对临床决策具有极高价值的生物学信息。它能够作为传统H&E病理分析的“超级增强包”,让医生的诊断和预测如虎添翼。
讨论与展望:一个属于“虚拟染色”的新时代
当然,HistoPlexer并非完美无缺。研究人员也坦诚地指出了它的一些局限性,例如在区分形态极其相似的T细胞和B细胞时偶尔会发生混淆 27,并且目前模型只覆盖了11种标志物,尚未包含更多稀有的细胞类型 。
但瑕不掩瑜,HistoPlexer的出现,为计算病理学乃至整个精准医疗领域打开了一扇全新的大门。它向我们展示了一个激动人心的未来:
普惠化的深度病理分析:未来,任何一家医院,只要能做最常规的H&E染色,就有潜力获得以往只有顶级研究中心才能负担得起的多重蛋白全景数据。这极大地降低了技术门槛和经济成本,有望让深度、全面的肿瘤微环境分析成为临床常规。
唤醒沉睡的数据金矿:全球各大医院和研究机构中,存储着数以亿计的H&E存量切片。HistoPlexer这样的技术,就像一把钥匙,能够解锁这些尘封已久的“数据金矿”,从中挖掘出前所未有的生物学洞见和临床价值。
加速新疗法与新靶点的发现:通过对海量虚拟蛋白图像进行分析,研究人员可以更高效地研究肿瘤与免疫系统的复杂互动,发现新的生物标志物,从而加速个性化治疗方案(尤其是免疫疗法)的开发。
总而言之,HistoPlexer不仅仅是一个聪明的算法,它更像是一个范式转换的起点。它让我们看到,借助AI的力量,我们可以从最常规、最基础的医学数据中,压榨出超乎想象的信息维度。
从“黑白”到“彩色”,从“形态”到“功能”,从“定性”到“定量”——HistoPlexer所代表的“虚拟多重染色”技术,或许将深刻改变我们理解、诊断和对抗癌症的方式,让真正的精准医疗,离我们每一个人都更近一步。
参考文献:
Andani, S., Chen, B., Ficek-Pascual, J. et al. Histopathology-based protein multiplex generation using deep learning. Nat Mach Intell 7, 1292–1307 (2025). https://doi.org/10.1038/s42256-025-01074-y